Human-Like Memory for AI Agents
When you’re building a chatbot or agent that needs to maintain continuity over long conversations, you hit a real wall pretty quick. Context windows are finite. The usual solution is straightforward: when you run out of space, summarize the old conversation and replace it with a compact version.
Sounds reasonable, doesn’t work.
The Sawtooth Problem
Every time you compress context into a summary, something gets lost. Details blur. Nuance evaporates. And worse, the agent loses the thread. The immersion breaks. The user notices and trust tanks.
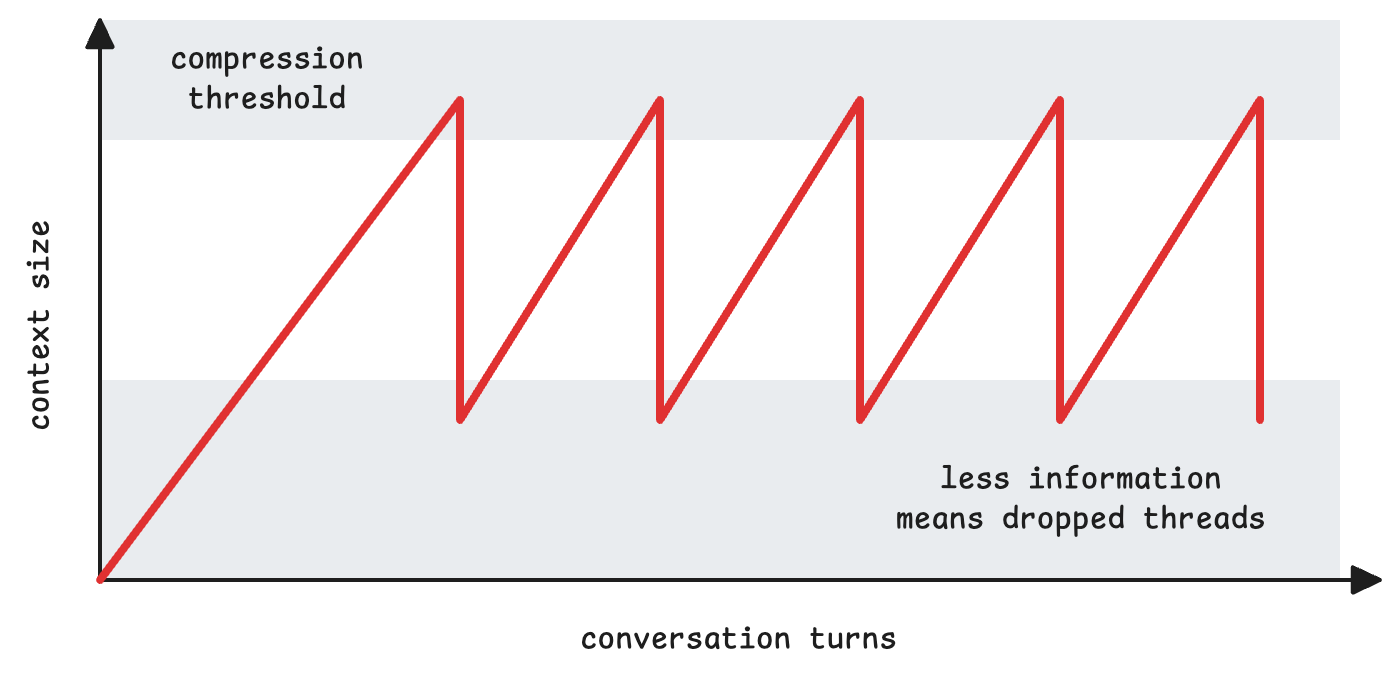
I ran into this building Arland, a chatbot powered by Claude. Every compression Arland would lose context, repeat himself, or suddenly not understand why we were talking about something. It worked but it felt broken.
The compression was turned into nicely formatted “notes” markdown file that Arland could use for long term storage. But by building it with a separate prompt, it injected its own “personality” into the mix, and worse, it lost vital bits of information.
Plus, summarization is expensive. You’re running separate inference passes on top of your main conversation loop. So you keep the context window uncomfortably small to avoid those costly compressions. Which means you compress more often. Which compounds the problem. It’s a spiral.
Another Way
Here’s the thing: you don’t actually need to compress context. You can prune it.
Most conversation is noise. Clarifications, tangents that went nowhere, corrections to earlier corrections, repeated confirmations. None of that needs to be summarized. It needs to be deleted.
What if, instead of trying to extract meaning from the old conversation, you just removed the garbage and kept what mattered?
The Three-Stage System
I ended up with a memory architecture that’s similar to how human memory actually works:
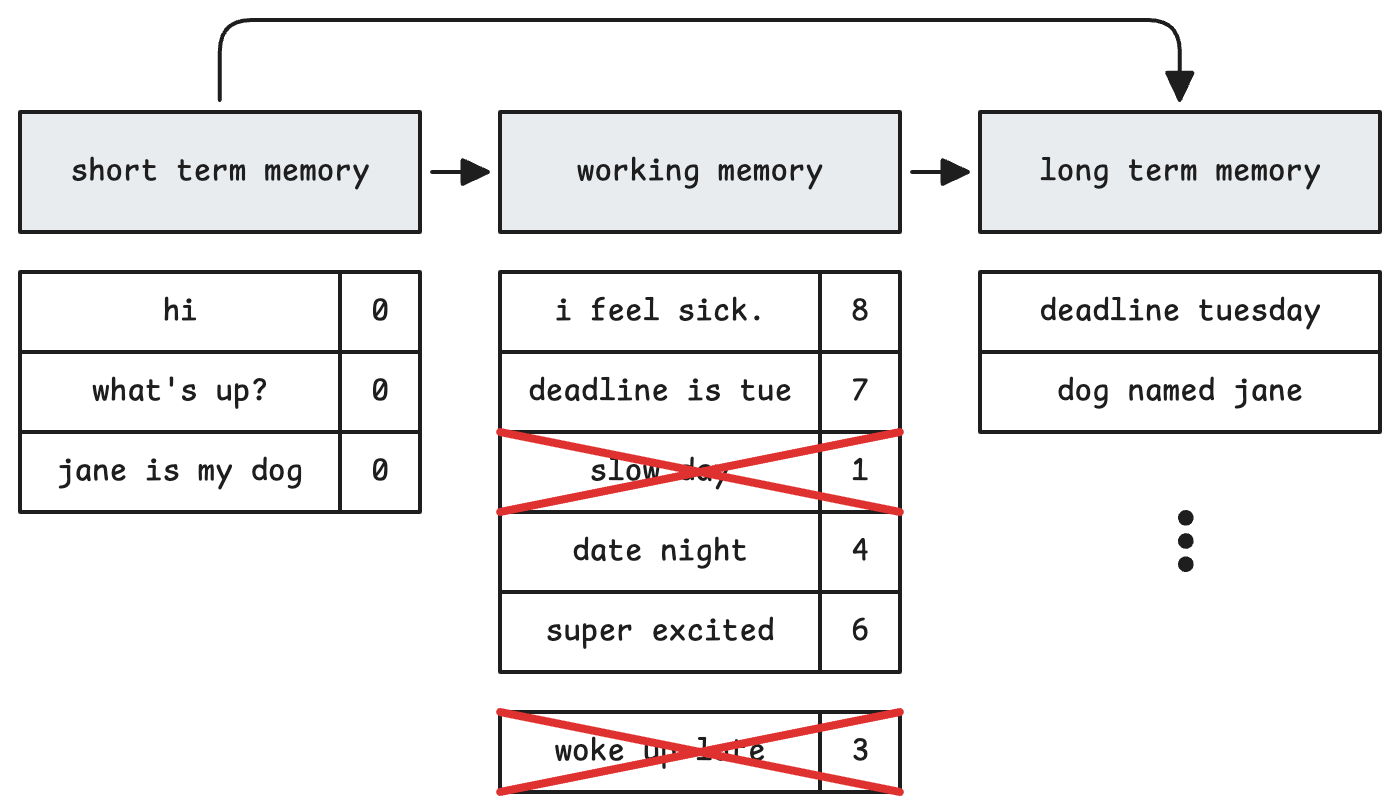
Short-term memory
The last few conversation turns are kept verbatim. No compression, no pruning. Full fidelity. Think of this as active awareness or what you’re currently focused on.
Working memory
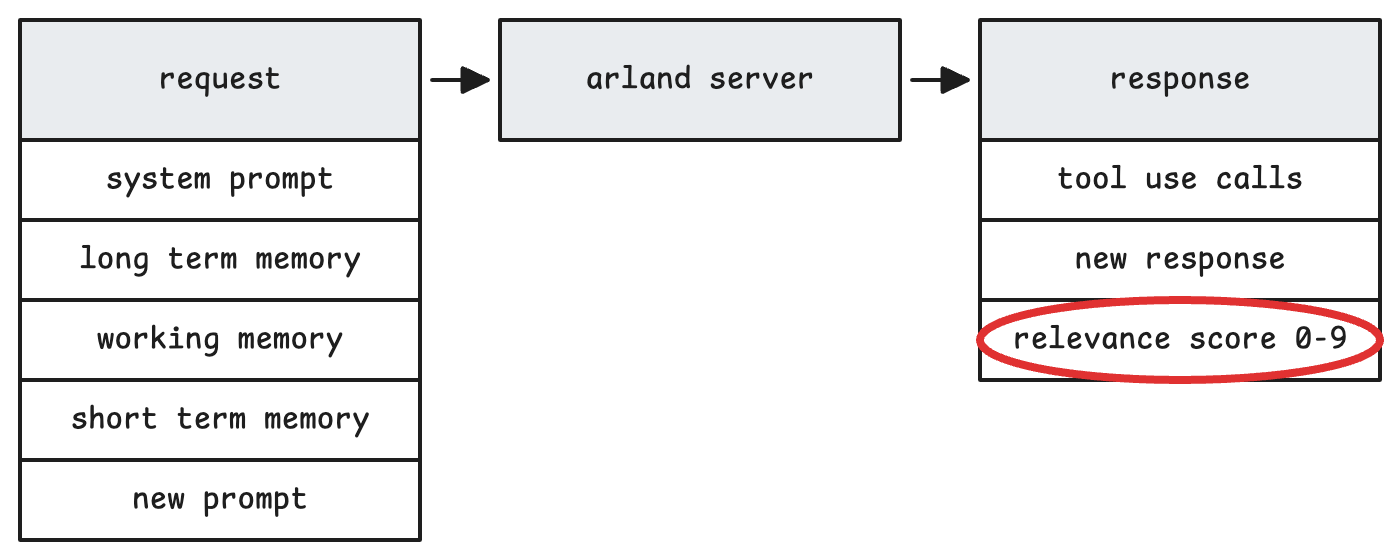
The next batch of turns (say 10), is kept in a pruned form. As each turn comes in, Claude scores it on relevance using criteria that matter for your specific agent. That scoring happens in the same prompt, so it’s cheap token-wise. When working memory hits capacity, the oldest lowest-scoring turn gets removed. Everything else ages down. Scores decay over time, so even highly relevant turns fade naturally as they get older. It’s like remembering yesterday better than last month.
Long-term memory
Persistent facts and context that stay around. Instead of having a separate summarization process, the agent updates its own long-term notes directly using tools. It decides what’s important enough to remember, rather than you guessing through a summarization prompt.
The beauty of this approach is that it mirrors how human memory works. So you get more natural conversation flow. Plus it’s cheaper to run.
Why This Works
You’re not fighting against the agent’s context window. You’re working with how attention and memory actually function in humans. The agent stays coherent because you’re preserving the signal and trimming the noise. No sawtooth. No sudden context loss.
And because scoring happens inline, you’re not burning tokens on separate summarization passes. The system is leaner and more responsive.
It’s still early days with this approach, but it’s already beating the old summarization-based system in ways that matter: immersion, consistency, and cost. I’ve lowered my short-term size to 3 turns, and working memory down to 6 turns. And Arland keeps up better than most people with conversation flow. The system prompting matters here, of course, and your mileage may vary.